publications
2025
- 3DHPESurveyArxiv
 3D Human Pose and Shape Estimation from LiDAR Point Clouds: A ReviewSalma Galaaoui, Eduardo Valle, David Picard, and 1 more author2025
3D Human Pose and Shape Estimation from LiDAR Point Clouds: A ReviewSalma Galaaoui, Eduardo Valle, David Picard, and 1 more author2025In this paper, we present a comprehensive review of 3D human pose estimation and human mesh recovery from in-the-wild LiDAR point clouds. We compare existing approaches across several key dimensions, and propose a structured taxonomy to classify these methods. Following this taxonomy, we analyze each method’s strengths, limitations, and design choices. In addition, (i) we perform a quantitative comparison of the three most widely used datasets, detailing their characteristics; (ii) we compile unified definitions of all evaluation metrics; and (iii) we establish benchmark tables for both tasks on these datasets to enable fair comparisons and promote progress in the field. We also outline open challenges and research directions critical for advancing LiDAR-based 3D human understanding. Moreover, we maintain an accompanying webpage that organizes papers according to our taxonomy and continuously update it with new studies: https://github.com/valeoai/3D-Human-Pose-Shape-Estimation-from-LiDAR
@article{galaaoui3DHumanPose2025, title = {3D Human Pose and Shape Estimation from LiDAR Point Clouds: A Review}, author = {Galaaoui, Salma and Valle, Eduardo and Picard, David and Samet, Nermin}, journal = {ArXiv}, year = {2025}, osf = {https://github.com/valeoai/3D-Human-Pose-Shape-Estimation-from-LiDAR}, preprint = {https://arxiv.org/abs/2509.12197}, type = {Preprint} } - CondimenCVPRW
 Condimen: Conditional Multi-Person Mesh RecoveryRomain Brégier, Fabien Baradel, Thomas Lucas, and 4 more authors2025
Condimen: Conditional Multi-Person Mesh RecoveryRomain Brégier, Fabien Baradel, Thomas Lucas, and 4 more authors2025Multi-person human mesh recovery (HMR) consists in detecting all individuals in a given input image, and predicting the body shape, pose, and 3D location for each detected person. The dominant approaches to this task rely on neural networks trained to output a single prediction for each detected individual. In contrast, we propose CondiMen, a method that outputs a joint parametric distribution over likely poses, body shapes, intrinsics and distances to the camera, using a Bayesian network. This approach offers several advantages. First, a probability distribution can handle some inherent ambiguities of this task-such as the uncertainty between a person’s size and their distance to the camera, or more generally the loss of information that occurs when projecting 3D data onto a 2D image. Second, the output distribution can be combined with additional information to produce better predictions, by using eg known camera or body shape parameters, or by exploiting multi-view observations. Third, one can efficiently extract the most likely predictions from this output distribution, making the proposed approach suitable for real-time applications. Empirically we find that our model i) achieves performance on par with or better than the state-of-the-art, ii) captures uncertainties and correlations inherent in pose estimation and iii) can exploit additional information at test time, such as multi-view consistency or body shape priors. CondiMen spices up the modeling of ambiguity, using just the right in-gredients on hand.
@article{bregierCondimenConditionalMultiPerson2025, author = {Brégier, Romain and Baradel, Fabien and Lucas, Thomas and Galaaoui, Salma and Armando, Matthieu and Weinzaepfel, Philippe and Rogez, Grégory}, title = {Condimen: Conditional Multi-Person Mesh Recovery}, journal = {IEEE- CVPR ROHBIN Workshop}, doi = {10.1109/CVPRW67362.2025.00373}, year = {2025}, preprint = {https://arxiv.org/abs/2412.13058}, type = {Conference Paper} }
2024
- MultiHMRECCV
 Multi-HMR: Multi-Person Whole-Body Human Mesh Recovery in a Single ShotFabien Baradel, Matthieu Armando, Salma Galaaoui, and 4 more authors2024
Multi-HMR: Multi-Person Whole-Body Human Mesh Recovery in a Single ShotFabien Baradel, Matthieu Armando, Salma Galaaoui, and 4 more authors2024We present Multi-HMR, a strong sigle-shot model for multi-person 3D human mesh recovery from a single RGB image. Predictions encompass the whole body, i.e., including hands and facial expressions, using the SMPL-X parametric model and 3D location in the camera coordinate system. Our model detects people by predicting coarse 2D heatmaps of person locations, using features produced by a standard Vision Transformer (ViT) backbone. It then predicts their whole-body pose, shape and 3D location using a new cross-attention module called the Human Prediction Head (HPH), with one query attending to the entire set of features for each detected person. As direct prediction of fine-grained hands and facial poses in a single shot, i.e., without relying on explicit crops around body parts, is hard to learn from existing data, we introduce CUFFS, the Close-Up Frames of Full-Body Subjects dataset, containing humans close to the camera with diverse hand poses. We show that incorporating it into the training data further enhances predictions, particularly for hands. Multi-HMR also optionally accounts for camera intrinsics, if available, by encoding camera ray directions for each image token. This simple design achieves strong performance on whole-body and body-only benchmarks simultaneously: a ViT-S backbone on 448x448 images already yields a fast and competitive model, while larger models and higher resolutions obtain state-of-the-art results.
@article{baradelMultiHMRMultipersonWholeBody2024, author = {Baradel, Fabien and Armando, Matthieu and Galaaoui, Salma and Brégier, Romain and Weinzaepfel, Philippe and Rogez, Grégory and Lucas, Thomas}, title = {Multi-HMR: Multi-Person Whole-Body Human Mesh Recovery in a Single Shot}, journal = {Springer Nature - ECCV 2024}, doi = {10.1007/978-3-031-73337-6_12}, year = {2024}, preprint = {https://arxiv.org/abs/2402.14654}, type = {Conference Paper} } - CroCoManCVPR
 Cross-view and Cross-pose Completion for 3D Human UnderstandingMatthieu Armando, Salma Galaaoui, Fabien Baradel, and 5 more authors2024
Cross-view and Cross-pose Completion for 3D Human UnderstandingMatthieu Armando, Salma Galaaoui, Fabien Baradel, and 5 more authors2024Human perception and understanding is a major domain of computer vision which like many other vision subdomains recently stands to gain from the use of large models pre-trained on large datasets. We hypothesize that the most common pre-training strategy of relying on general purpose object-centric image datasets such as ImageNet is limited by an important domain shift. On the other hand collecting domain-specific ground truth such as 2D or 3D labels does not scale well. Therefore we propose a pre-training approach based on self-supervised learning that works on human-centric data using only images. Our method uses pairs of images of humans: the first is partially masked and the model is trained to reconstruct the masked parts given the visible ones and a second image. It relies on both stereoscopic (cross-view) pairs and temporal (cross-pose) pairs taken from videos in order to learn priors about 3D as well as human motion. We pre-train a model for body-centric tasks and one for hand-centric tasks. With a generic transformer architecture these models outperform existing self-supervised pre-training methods on a wide set of human-centric downstream tasks and obtain state-of-the-art performance for instance when fine-tuning for model-based and model-free human mesh recovery.
@article{armandoCrossViewCrossPoseCompletion2024, author = {Armando, Matthieu and Galaaoui, Salma and Baradel, Fabien and Lucas, Thomas and Leroy, Vincent and Brégier, Romain and Weinzaepfel, Philippe and Rogez, Grégory}, title = {Cross-view and Cross-pose Completion for 3D Human Understanding}, journal = {IEEE - CVPR 2024}, doi = {10.1109/CVPR52733.2024.00150}, year = {2024}, preprint = {https://arxiv.org/abs/2311.09104}, type = {Conference Paper} } - SHOWMeCVIU
 SHOWMe: Robust Object-Agnostic Hand-Object 3D Reconstruction from RGB videoAnilkumar Swamy, Vincent Leroy, Philippe Weinzaepfel, and 6 more authors2024
SHOWMe: Robust Object-Agnostic Hand-Object 3D Reconstruction from RGB videoAnilkumar Swamy, Vincent Leroy, Philippe Weinzaepfel, and 6 more authors2024In this paper, we tackle the problem of detailed hand-object 3D reconstruction from monocular video with unknown objects, for applications where the required accuracy and level of detail is important, e.g. object hand-over in human–robot collaboration, or manipulation and contact point analysis. While the recent literature on this topic is promising, the accuracy and generalization abilities of existing methods are still lacking. This is due to several limitations, such as the assumption of known object class or model for a small number of instances, or over-reliance on off-the-shelf keypoint and structure-from-motion methods for object-relative viewpoint estimation, prone to complete failure with previously unobserved, poorly textured objects or hand-object occlusions. To address previous method shortcomings, we present a 2-stage pipeline superseding state-of-the-art (SotA) performance on several metrics. First, we robustly retrieve viewpoints relying on a learned pairwise camera pose estimator trainable with a low data regime, followed by a globalized Shonan pose averaging. Second, we simultaneously estimate detailed 3D hand-object shapes and refine camera poses using a differential renderer-based optimizer. To better assess the out-of-distribution abilities of existing methods, and to showcase our methodological contributions, we introduce the new SHOWMe benchmark dataset with 96 sequences annotated with poses, millimetric textured 3D shape scans, and parametric hand models, introducing new object and hand diversity. Remarkably, we show that our method is able to reconstruct 100% of these sequences as opposed to SotA Structure-from-Motion (SfM) or hand-keypoint-based pipelines, and obtains reconstructions of equivalent or better precision when existing methods do succeed in providing a result. We hope these contributions lead to further research under harder input assumptions. The dataset can be downloaded at https://download.europe.naverlabs.com/showme.
@article{swamySHOWMeRobustObjectagnostic2024, author = {Swamy, Anilkumar and Leroy, Vincent and Weinzaepfel, Philippe and Baradel, Fabien and Galaaoui, Salma and Brégier, Romain and Armando, Matthieu and Franco, Jean-Sebastien and Rogez, Grégory}, title = {SHOWMe: Robust Object-Agnostic Hand-Object 3D Reconstruction from RGB video}, journal = {ELSEVIER - CVIU 2024 Special issue on Advances in Deep Learning for Human-Centric Visual Understanding}, doi = {10.1016/j.cviu.2024.104073}, year = {2024}, type = {Journal Article} }
2023
- SHOWMeICCVW
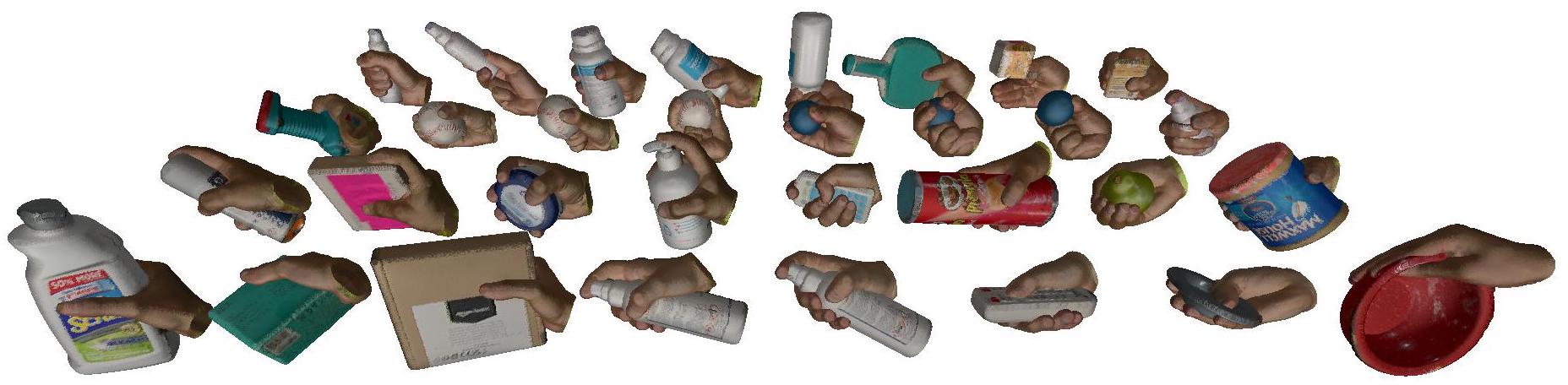 SHOWMe: Benchmarking Object-agnostic Hand-Object 3D ReconstructionAnilkumar Swamy, Vincent Leroy, Philippe Weinzaepfel, and 6 more authors2023
SHOWMe: Benchmarking Object-agnostic Hand-Object 3D ReconstructionAnilkumar Swamy, Vincent Leroy, Philippe Weinzaepfel, and 6 more authors2023Recent hand-object interaction datasets show limited real object variability and rely on fitting the MANO parametric model to obtain groundtruth hand shapes. To go beyond these limitations and spur further research, we introduce the SHOWMe dataset which consists of 96 videos, annotated with real and detailed hand-object 3D textured meshes. Following recent work, we consider a rigid hand-object scenario, in which the pose of the hand with respect to the object remains constant during the whole video sequence. This assumption allows us to register sub-millimeter-precise groundtruth 3D scans to the image sequences in SHOWMe. Although simpler, this hypothesis makes sense in terms of applications where the required accuracy and level of detail is important e.g., object hand-over in human-robot collaboration, object scanning, or manipulation and contact point analysis. Importantly, the rigidity of the hand-object systems allows to tackle video-based 3D reconstruction of unknown handheld objects using a 2-stage pipeline consisting of a rigid registration step followed by a multi-view reconstruction (MVR) part. We carefully evaluate a set of non-trivial baselines for these two stages and show that it is possible to achieve promising object-agnostic 3D hand-object reconstructions employing an SfM toolbox or a hand pose estimator to recover the rigid transforms, and off-the-shelf MVR algorithms. However, these methods remain sensitive to the initial camera pose estimates which might be imprecise due to lack of textures on the objects or heavy occlusions of the hands, leaving room for improvements in the reconstruction. Code and dataset are available at https://europe.naverlabs.com/research/showme/.
@article{swamySHOWMeBenchmarkingObjectagnostic2023, author = {Swamy, Anilkumar and Leroy, Vincent and Weinzaepfel, Philippe and Baradel, Fabien and Galaaoui, Salma and Brégier, Romain and Armando, Matthieu and Franco, Jean-Sebastien and Rogez, Grégory}, title = {SHOWMe: Benchmarking Object-agnostic Hand-Object 3D Reconstruction}, journal = {IEEE - ICCV ACRV Workshop}, doi = {10.1109/ICCVW60793.2023.00208}, year = {2023}, preprint = {https://arxiv.org/abs/2309.10748}, type = {Conference Paper} }